From Hieroglyphs to Hangul: An Analysis of Linguistic Symbols in Contemporary Languages
From the slender, vertical columns of traditional Mongolian script to the flowing, asymmetric forms of the Ge’ez script used in Ethiopian and Eritrean languages, humans have devised numerous methods to record their thoughts. Though the variety of individual scripts — written symbols conveying linguistic meaning — is vast, only a handful of writing systems have stood the test of time. In reality, all writing systems in use, past and present, can be categorized into six distinct types:
Alphabets: Systems comprising symbols for individual vowels and consonants, with examples including languages from Europe like English, Spanish, and Russian, utilizing variations of the Latin and Cyrillic alphabets, respectively.Syllabaries: Each symbol represents a syllable rather than a single sound. Languages using syllabaries include Japanese (with Hiragana and Katakana) and Cherokee.Alpha-syllabaries (Abugidas): Merging alphabets and syllabaries, each consonant-vowel sequence is written as a unit. Examples are Devanagari, used in Hindi and Sanskrit, and Ge’ez in Amharic and Tigrinya.Abjads: Consonant-based scripts with minimal or absent vowel indication. Arabic script (used in Arabic and Persian) and Hebrew script (used in Hebrew) are examples.Logographic Systems: Symbols represent words or morphemes. Mandarin and Cantonese using Chinese characters, and Kanji in Japanese, are examples.Featural Scripts: Represent phonetic features of the phonemes they symbolize, like the Korean Hangul, where letter shapes phonetically match the shape of the mouth when making the corresponding sound.
How prevalent are these writing systems? It depends how you measure. To illustrate, I turned to GPT to compile a dataset of the most commonly spoken languages and the writing systems they use.
Dataset Compilation
I focused on the world’s top 50 most commonly spoken languages with over 10 million native (L1) speakers. Considering English’s role as a global lingua franca, it notably has a larger L2 (second language) speaker population than L1.
After several iterations of prompt crafting with GPT, I settled on a prompt designed to curate a dataset that would capture a detailed snapshot of language use and writing systems worldwide. Here is the one I used:
Please help me create a dataset. The dataset will contain the following fields: LanguageName, WritingSystem, L1Population, L2Population, L1L2PopulationCombined, Family, Branch, ContinentOriginated. For the list of 50 languages that you gave me, create a csv file with these fields. Include the header with the column names. Use your best judgement for the WritingSystem column, which can take the following values: “Logographic”, “Syllabary”, “Alphabet”, “Alpha-syllabary”, “Featural”, “Abjad”. For languages with more than one applicable WritingSystem, separate them with a semi-colon.
The next step was to verify the data in the file. I cross-referenced L1 and L2 population estimates with authoritative sources like Ethnologue and the CIA World Factbook, adjusting some figures for accuracy. For the linguistic classifications, I verified the results using Glottolog and Ethnologue. Finally, I personally verified each of the 50 classifications for the WritingSystem field. I recorded only a few tweaks I made to its judgements on WritingSystem: * I tweaked the result for Sindhi which should be both abjad + alpha-syllabary * I changed GPT’s result for Burmese ,which should be alpha-syllabary * For ContinentOrigin, GPT rather diplomatically put Turkic down as “Asia/Europe” which I ultimately didn’t correct
Overall, the GPT-produced results were highly accurate, and produced high-quality assessments even for difficult classifications of obscure languages like Hausa (Abjad; Alphabet) and Uzbek (Abjad; Alphabet).
Analysis
Plotting languages by their L1 and L2 populations highlighted a mix of alphabets and alpha-syllabaries, with Chinese as a significant outlier due to its logographic system. Logographries are rare among the most common world languages.
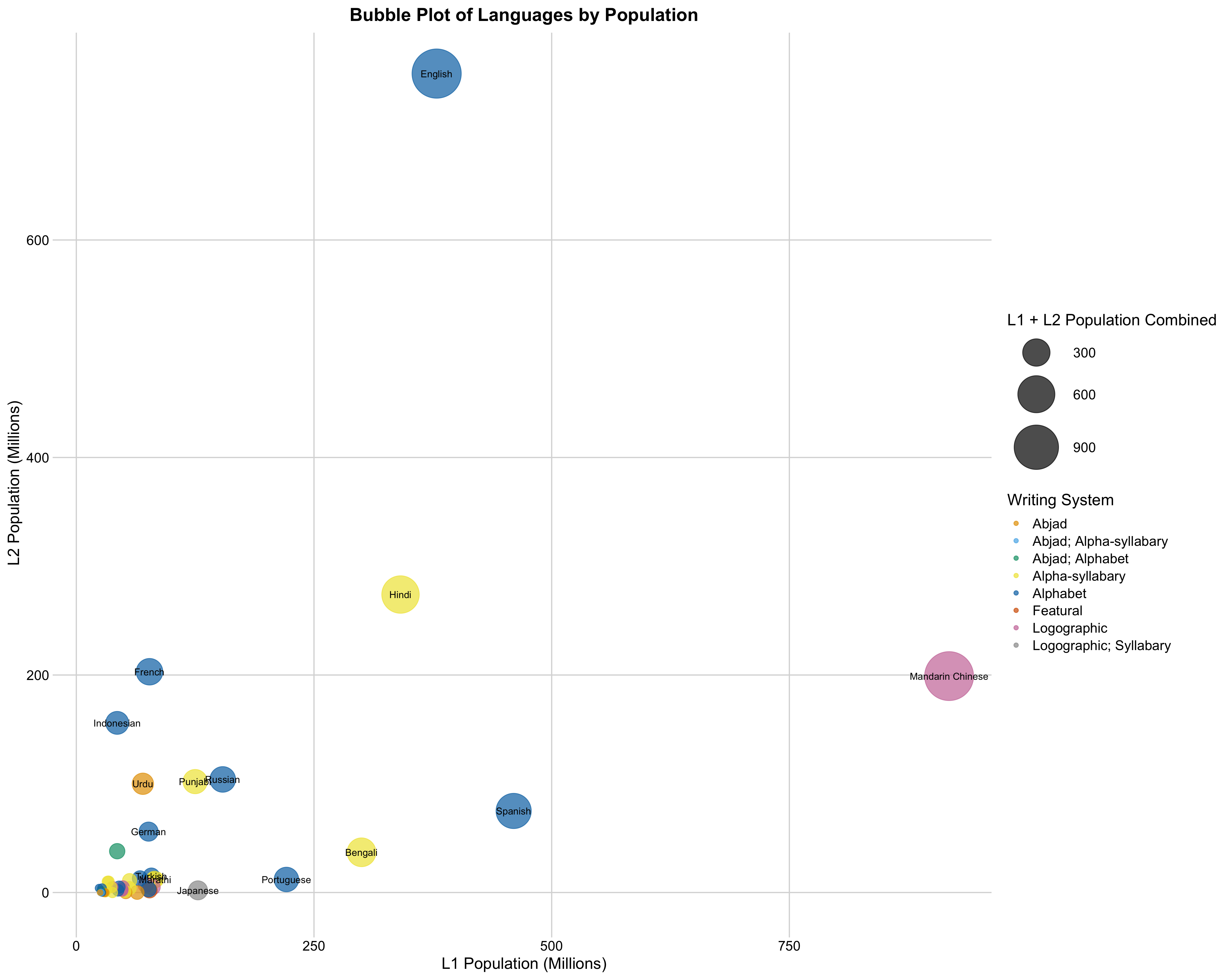
But just how common are each of the writing systems in use? The aggregated statistics below highlight that alphabets have the highest combined L1L2 population. By GPT’s approximation, alphabets are used by more than a billion more people than alpha-syllabaries, the next most common. However, alpha-syllabaries boast the most languages within the top 50, largely due to the linguistically diverse Indian subcontinent (except for Indonesian languages Javanese and Sundanese).
Evaluating the diversity and adaptability of writing systems involves more than just tallying the number of languages they encompass. Another important measure is their spread across different linguistic families, branches, and continents. By this yardstick, alphabets and abjads lead in terms of versatility, serving as the primary scripts for a wide array of linguistic groups worldwide. On the other hand, logographic systems, predominantly confined to the Sino-Tibetan languages (with the notable exception of Japanese, which defies classification in several respects), demonstrate less adaptability across varied linguistic landscapes.
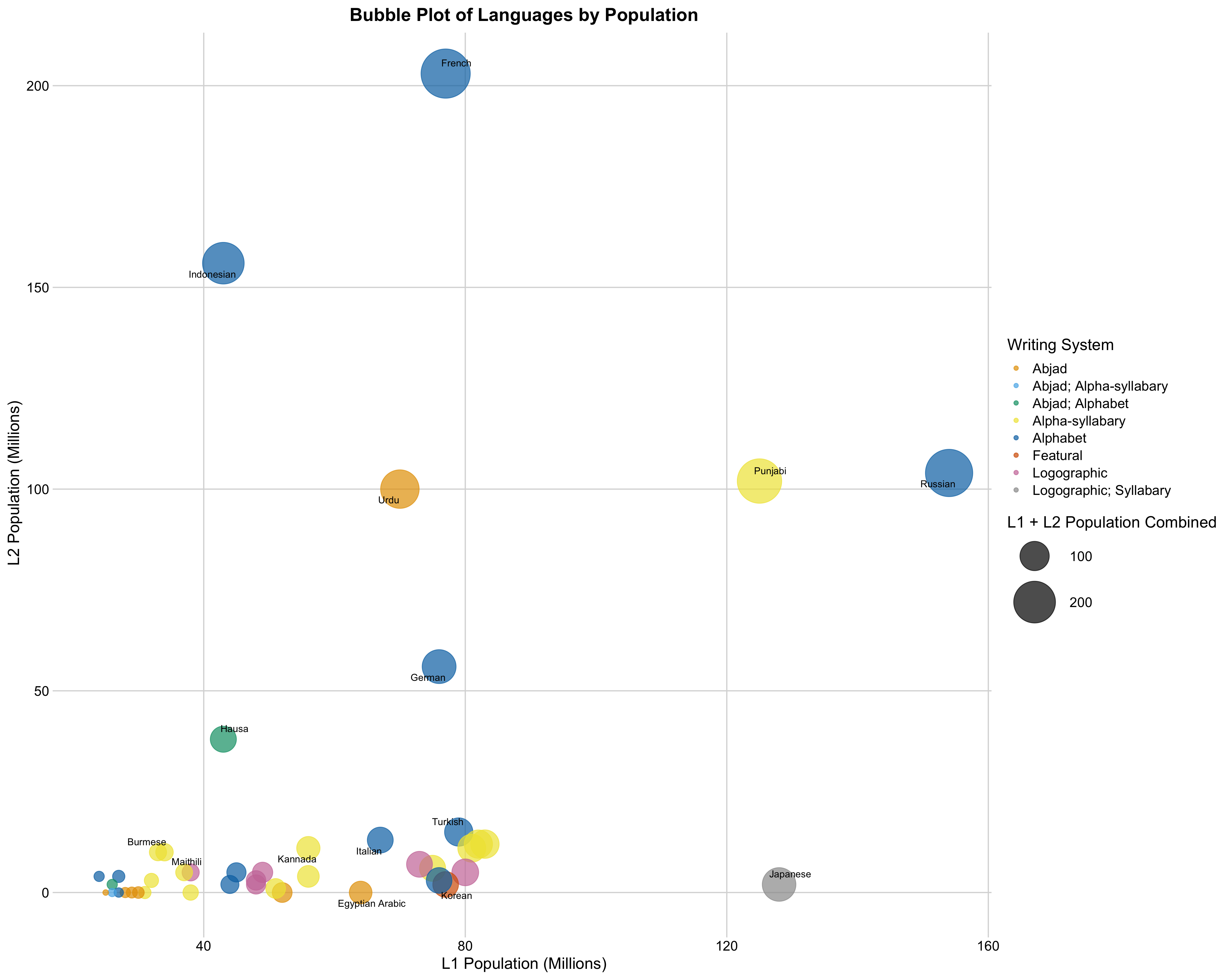
To filter out the languages in the most populous countries, I display only countries with L1 populations below 200M and L2 populations below 250M. Again, we see a mix of alphabets and alpha-syllabaries, but Urdu and Japanese also join the mix. Languages that use the Arabic script are all abjads, and we see other Arabic-influenced languages near the origin.
Japanese is in a class of its own. It is unique in using a logographic system outside of the Sinitic languages and combines this with not one, but two syllabaries: hiragana for native words and katakana for foreign loanwords. Japanese is the sole example of this combination in this dataset, and the only one that uses a syllabary. Other languages employing syllabaries are uncommon and obscure, like Cherokee, Yi, and Vai. This underscores Japanese’s unique linguistic position.
So is Japanese truly the biggest linguistic and orthographic oddity? To get a sense of which is the biggest anomaly, I used a hierarchical clustering algorithm to group together common languages. The family of languages cluster together sensibly, with Indo-European, South Indian, Sino-Tibetan, and Arabic languages forming distinct groups. Towards the bottom, however, appear “outcast” languages that refuse to cluster with others. The two linguistic nonconformists are Japanese and Korean.
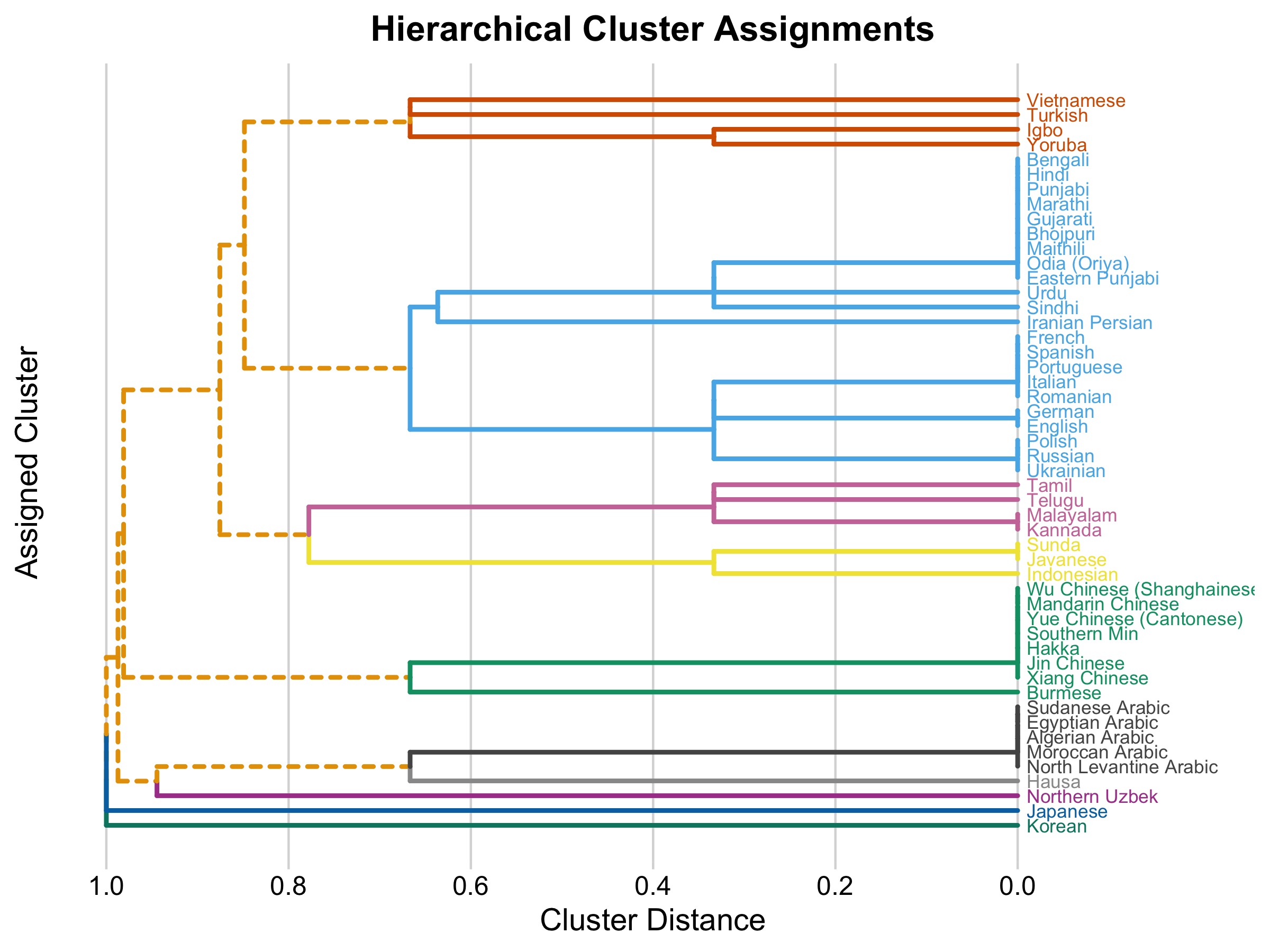
While its linguistic history is particular, Korean’s writing system is perhaps the most unique of all. Korean is the only language in use today with a featural writing system, Hangul, designed specifically to be easy to learn and use. Created in the 15th century by King Sejong the Great, its “letters” mimic the shapes of the speech organs, making it easy to learn and use. Hangul efficiently combines 14 consonants and 10 vowels into syllable blocks, enabling high literacy rates in pre-modern Korea. This logical structure sets it apart as one of the most innovative writing systems in the world.
Conclusion
This analysis clarified the distinctiveness of writing systems like featural scripts and syllabaries, the adaptability of alphabets and abjads, and the geographical specificity of alpha-syllabaries and logographries. It was revealing to discover that only a few writing systems endured across history, with ancient languages often blending these six systems. For instance, Ancient Egyptian hieroglyphs merged logographic and alphabetic elements.
The project also demonstrated the efficiency of using GPT for quickly and effectively researching ideas. Five minutes of crafting prompts yielded a dataset ready for analysis with statistical tools. GPT significantly lowered the barriers to exploring such questions and allowed me to quickly pursue a research whim that would have been prohibitively time-consuming and resource-intensive to conduct on my own just a year ago.